|
All 5 books, Edward Tufte paperback $180
All 5 clothbound books, autographed by ET $280
Visual Display of Quantitative Information
Envisioning Information
Visual Explanations
Beautiful Evidence
Seeing With Fresh Eyes
catalog + shopping cart
|
Edward Tufte e-books Immediate download to any computer: Visual and Statistical Thinking $5
The Cognitive Style of Powerpoint $5
Seeing Around + Feynman Diagrams $5
Data Analysis for Politics and Policy $9
catalog + shopping cart
New ET Book
Seeing with Fresh Eyes:
catalog + shopping cart
Meaning, Space, Data, Truth |
Analyzing/Presenting Data/Information All 5 books + 4-hour ET online video course, keyed to the 5 books. |


Here are a few pages from a draft of a Beautiful Evidence chapter (which is 16 pages long in the published book) on evidence corruption, along with some of the comments on this draft material.
The emphasis is on consuming presentations, on what alert members of an audience or readers of a report should look for in assessing the credibility of the presenter.
 |
 |
 |
 |
 |
 |
 |
 |
 |
-- Edward Tufte
In "The Bell Curve," Atul Gawande discusses the moral and social consequences of presenting, or not presenting, medical statistics.
To fix medicine, Berwick maintained, we need to do two things: measure ourselves and be more open about what we are doing. This meant routinely comparing the performance of doctors and hospitals, looking at everything from complication rates to how often a drug ordered for a patient is delivered correctly and on time. And, he insisted, hospitals should give patients total access to the information. He argued that openness would drive improvement, if simply through embarrassment. It would make it clear that the well-being and convenience of patients, not doctors, were paramount. It would also serve a fundamental moral good, because people should be able to learn about anything that affects their lives.
...
Once we acknowledge that, no matter how much we improve our average, the bell curve isn't going away, we're left with all sorts of questions. Will being in the bottom half be used against doctors in lawsuits? Will we be expected to tell our patients how we score? Will our patients leave us? Will those at the bottom be paid less than those at the top? The answer to all these questions is likely yes. Recently, there has been a lot of discussion, for example, about "paying for quality." (No one ever says "docking for mediocrity," but it amounts to the same thing.) Congress has discussed the idea in hearings. Insurers like Aetna and the Blue Cross-Blue Shield companies are introducing it across the country. Already, Medicare has decided not to pay surgeons for intestinal transplantation operations unless they achieve a predefined success rate. Not surprisingly, this makes doctors anxious. I recently sat in on a presentation of the concept to an audience of doctors. By the end, some in the crowd were practically shouting with indignation: We're going to be paid according to our grades? Who is doing the grading? For God's sake, how? We in medicine are not the only ones being graded nowadays. Firemen, C.E.O.s, and salesmen are. Even teachers are being graded, and, in some places, being paid accordingly. Yet we all feel uneasy about being judged by such grades. They never seem to measure the right things. They don't take into account circumstances beyond our control. They are misused; they are unfair. Still, the simple facts remain: there is a bell curve in all human activities, and the differences you measure usually matter.
...
The hardest question for anyone who takes responsibility for what he or she does is, What if I turn out to be average? If we took all the surgeons at my level of experience, compared our results, and found that I am one of the worst, the answer would be easy: I'd turn in my scalpel. But what if I were a C? Working as I do in a city that's mobbed with surgeons, how could I justify putting patients under the knife? I could tell myself, Someone's got to be average. If the bell curve is a fact, then so is the reality that most doctors are going to be average. There is no shame in being one of them, right? Except, of course, there is. Somehow, what troubles people isn't so much being average as settling for it. Everyone knows that averageness is, for most of us, our fate. And in certain matters--looks, money, tennis--we would do well to accept this. But in your surgeon, your child's pediatrician, your police department, your local high school? When the stakes are our lives and the lives of our children, we expect averageness to be resisted. And so I push to make myself the best. If I'm not the best already, I believe wholeheartedly that I will be. And you expect that of me, too. Whatever the next round of numbers may say.Published in the New Yorker.
-- Niels Olson (email)
Posner on Blink
An interesting and powerful critique of an evidence presentation is Richard A. Posner's review of Malcolm Gladwell's book Blink: The Power of Thinking without Thinking. Posner makes me seem bland!
Published in The New Republic.Blinkered
THERE ARE TWO TYPES OF THINKING, to oversimplify grossly. We may call them intuitive and articulate. The first is the domain of hunches, snap judgments, emotional reactions, and first impressions--in short, instant responses to sensations. Obviously there is a cognitive process involved in such mental processes; one is responding to information. But there is no conscious thought, because there is no time for it. The second type of thinking is the domain of logic, deliberation, reasoned discussion, and scientific method. Here thinking is conscious: it occurs in words or sentences or symbols or concepts or formulas, and so it takes time. Articulate thinking is the model of rationality, while intuitive thinking is often seen as primitive, "emotional" in a derogatory sense, the only type of thinking of which animals are capable; and so it is articulate thinking that distinguishes human beings from the "lower" animals.
When, many years ago, a judge confessed that his decisions were based largely on hunch, this caused a bit of a scandal; but there is increasing recognition that while judicial opinions, in which the judge explains his decision, are models of articulate thinking, the decision itself--the outcome, the winner--will often come to the judge in a flash. But finally the contrast between intuitive and articulate thinking is overdrawn: it ignores the fact that deliberative procedures can become unconscious simply by becoming habitual, without thereby being intuitive in the sense of pre-verbal or emotional; and that might be the case with judicial decisions, too.
Malcolm Gladwell, a journalist, wishes to bring to a popular audience the results of recent research in psychology and related disciplines, such as neuroscience, which not only confirm the importance of intuitive cognition in human beings but also offer a qualified vindication of it. He argues that intuition is often superior to articulate thinking. It often misleads, to be sure; but with an awareness of the pitfalls we may be able to avoid them.
As Exhibit A for the superiority of intuitive to articulate thinking, Gladwell offers the case of a purported ancient Greek statue that was offered to the Getty Museum for $10 million. Months of careful study by a geologist (to determine the age of the statue) and by the museum's lawyers (to trace the statue's provenance) convinced the museum that it was genuine. But when historians of ancient art looked at it, they experienced an "intuitive revulsion," and indeed it was eventually proved to be a fake.
The example is actually a bad one for Gladwell's point, though it is a good illustration of the weakness of this book, which is a series of loosely connected anecdotes, rich in "human interest" particulars but poor in analysis. There is irony in the book's blizzard of anecdotal details. One of Gladwell's themes is that clear thinking can be overwhelmed by irrelevant information, but he revels in the irrelevant. An anecdote about food tasters begins: "One bright summer day, I had lunch with two women who run a company in New Jersey called Sensory Spectrum." The weather, the season, and the state are all irrelevant. And likewise that hospital chairman Brendan Reilly "is a tall man with a runner's slender build." Or that "inside, JFCOM [Joint Forces Command] looks like a very ordinary office building.... The business of JFCOM, however, is anything but ordinary." These are typical examples of Gladwell's style, which is bland and padded with cliches.
But back to the case of the Greek statue. It illustrates not the difference between intuitive thinking and articulate thinking, but different articulate methods of determining the authenticity of a work of art. One method is to trace the chain of title, ideally back to the artist himself (impossible in this case); another is to perform chemical tests on the material of the work; and a third is to compare the appearance of the work to that of works of art known to be authentic. The fact that the first two methods happened to take longer in the particular case of the Getty statue is happenstance. Had the seller produced a bill of sale from Phidias to Cleopatra, or the chemist noticed that the statue was made out of plastic rather than marble, the fake would have been detected in the blink of an eye. Conversely, had the statue looked more like authentic statues of its type, the art historians might have had to conduct a painstakingly detailed comparison of each feature of the work with the corresponding features of authentic works. Thus the speed with which the historians spotted this particular fake is irrelevant to Gladwell's thesis. Practice may not make perfect, but it enables an experienced person to arrive at conclusions more quickly than a neophyte. The expert's snap judgment is the result of a deliberative process made unconscious through habituation.
As one moves from anecdote to anecdote, the reader of Blink quickly realizes, though its author does not, that a variety of interestingly different mental operations are being crammed unhelpfully into the "rapid cognition" pigeonhole. In one anecdote, Dr. Lee Goldman discovers that the most reliable quick way of determining whether a patient admitted to a hospital with chest pains is about to have a heart attack is by using an algorithm based on just four data: the results of the patient's electrocardiogram, the pain being unstable angina, the presence of fluid in the lungs, and systolic blood pressure below one hundred. There is no diagnostic gain, Goldman found, from also knowing whether the patient has the traditional risk factors for heart disease, such as being a smoker or suffering from diabetes. In fact, there is a diagnostic loss, because an admitting doctor who gave weight to these factors (which are indeed good long-term predictors of heart disease) would be unlikely to admit a patient who had none of the traditional risk factors but was predicted by the algorithm to be about to have a heart attack.
TO ILLUSTRATE WHERE RAPID cognition can go wrong, Gladwell introduces us to Bob Golomb, an auto salesman who attributes his success to the fact that "he tries never to judge anyone on the basis of his or her appearance." More unwitting irony here, for Gladwell himself is preoccupied with people's appearances. Think of Reilly, with his runner's build; or John Gottman, who claims to be able by listening to a married couple talk for fifteen minutes to determine with almost 90 percent accuracy whether they will still be married in fifteen years, and whom Gladwell superfluously describes as "a middle-aged man with owl-like eyes, silvery hair, and a neatly trimmed beard. He is short and very charming...." And then there is "Klin, who bears a striking resemblance to the actor Martin Short, is half Israeli and half Brazilian, and he speaks with an understandably peculiar accent." Sheer clutter.
Golomb, the successful auto salesman, is contrasted with the salesmen in a study in which black and white men and women, carefully selected to be similar in every aspect except race and sex, pretended to shop for cars. The blacks were quoted higher prices than the whites, and the women higher prices than the men. Gladwell interprets this to mean that the salesmen lost out on good deals by judging people on the basis of their appearance. But the study shows no such thing. The authors of the study did not say, and Gladwell does not show, and Golomb did not suggest, that auto salesmen are incorrect in believing that blacks and women are less experienced or assiduous or pertinacious car shoppers than white males and therefore can be induced to pay higher prices. The Golomb story contained no mention of race or sex. (Flemington, where Golomb works, is a small town in central New Jersey that is only 3 percent black.) And when he said he tries not to judge a person on the basis of the person's appearance, it seems that all he meant was that shabbily dressed and otherwise unprepossessing shoppers are often serious about buying a car. "Now, if you saw this man [a farmer], with his coveralls and his cow dung, you'd figure he was not a worthy customer. But in fact, as we say in the trade, he's all cashed up."
It would not occur to Gladwell, a good liberal, that an auto salesman's discriminating on the basis of race or sex might be a rational form of the "rapid cognition" that he admires. If two groups happen to differ on average, even though there is considerable overlap between the groups, it may be sensible to ascribe the group's average characteristics to each member of the group, even though one knows that many members deviate from the average. An individual's characteristics may be difficult to determine in a brief encounter, and a salesman cannot afford to waste his time in a protracted one, and so he may quote a high price to every black shopper even though he knows that some blacks are just as shrewd and experienced car shoppers as the average white, or more so. Economists use the term "statistical discrimination" to describe this behavior. It is a better label than stereotyping for what is going on in the auto-dealer case, because it is more precise and lacks the distracting negative connotation of stereotype, defined by Gladwell as "a rigid and unyielding system." But is it? Think of how stereotypes of professional women, Asians, and homosexuals have changed in recent years. Statistical discrimination erodes as the average characteristics of different groups converge.
Gladwell reports an experiment in which some students are told before a test to think about professors and other students are told to think about soccer hooligans, and the first group does better on the test. He thinks this result shows the fallacy of stereotypical thinking. The experimenter claimed it showed that people are so suggestible that they can be put in a frame of mind in which they feel smarter and therefore perform smarter. The claim is undermined by a literature of which Gladwell seems unaware, which finds that self-esteem is correlated negatively rather than positively with academic performance. Yet, true or false, the claim is unrelated to statistical discrimination, which is a matter of basing judgments on partial information.
The average male CEO of a Fortune 500 company is significantly taller than the average American male, and Gladwell offers this as another example of stereotypical thinking. That is not very plausible; a CEO is selected only after a careful search to determine the candidate's individual characteristics. Gladwell ignores the possibility that tall men are disproportionately selected for leadership positions because of personality characteristics that are correlated with height, notably self-confidence and a sense of superiority perhaps derived from experiences in childhood, when tall boys lord it over short ones. Height might be a tiebreaker, but it would be unlikely to land the job for a candidate whom an elaborate search process revealed to be less qualified than a shorter candidate.
GLADWELL APPLAUDS THE rule that a police officer who stops a car driven by someone thought to be armed should approach the seated driver from the rear on the driver's side but pause before he reaches the driver, so that he will be standing slightly behind where the driver is sitting. The driver, if he wants to shoot the officer, will have to twist around in his seat, and this will give the officer more time to react. Gladwell says that this rule is designed to prevent what he calls "temporary autism." This is one of many cutesy phrases and business-guru slogans in which this book abounds. Others include "mind- blindness," "listening with your eyes," "thin slicing"--which means basing a decision on a small amount of the available information--and the "Warren Harding error," which is thinking that someone who looks presidential must have the qualities of a good president.
Autistic people treat people as inanimate objects rather than as thinking beings like themselves, and as a result they have trouble predicting behavior. Gladwell argues that a police officer who fears that his life is in danger will be unable to read the suspect's face and gestures for reliable clues to intentions (Gladwell calls this "mind reading") and is therefore likely to make a mistake; he is "mind-blinded," as if he were autistic. The rule gives him more time to decide what the suspect's intentions are. It seems a sensible rule, but the assessment of it gains nothing from a reference to autism. Obviously you are less likely to shoot a person in mistaken self-defense the more time you have in which to assess his intentions.
Gladwell endorses a claim by the psychologist Paul Ekman that careful study of a person's face while he is speaking will reveal unerringly whether he is lying. Were this true, the implications would be revolutionary. The CIA could discard its lie detectors. Psychologists trained by Ekman could be hired to study videotapes of courtroom testimony and advise judges and jurors whom to believe and whom to convict of perjury. Ekman's "Facial Action Coding System" would dominate the trial process. Gladwell is completely credulous about Ekman's claims. Ekman told him that he studied Bill Clinton's facial expressions during the 1992 campaign and told his wife, "This is a guy who wants to be caught with his hand in the cookie jar, and have us love him for it anyway." This self-serving testimony is no evidence of anything. The natural follow-up question for Gladwell to have asked would have been whether, when Ekman saw the videotape of Clinton's deposition during the run-up to his impeachment, he realized that Clinton was lying. He didn't ask that question. Nor does he mention the flaws that critics have found in Ekman's work.
As with Gladwell's other tales, the Ekman story is not actually about the strengths and the weaknesses of rapid cognition. It took Ekman years to construct his Facial Action Coding System, which Gladwell tells us fills a five- hundred-page binder. Now, it is perfectly true that we can often infer a person's feelings, intentions, and other mental dispositions from a glance at his face. But people are as skillful at concealing their feelings and intentions as they are at reading them in others--hence the need for the FACS, which is itself a product of articulate thinking.
So Gladwell should not have been surprised by the results of an experiment to test alternative methods of discovering certain personal characteristics of college kids, such as emotional stability. One method was to ask the person's best friends; another was to ask strangers to peek inside the person's room. The latter method proved superior. People conceal as well as reveal themselves in their interactions with their friends. In arranging their rooms, they are less likely to be trying to make an impression, so the stranger will not be fooled by prior interactions with the person whose room it is. The better method happened to be the quicker one. But it wasn't better because it was quicker.
REMEMBER JFCOM? In 2002, it conducted a war game called "Millennium Challenge" in anticipation of the U.S. invasion of Iraq. As commander of the "Red Team" (the adversary in a war game), JFCOM chose a retired Marine general named Paul Van Riper. Oddly, Gladwell never mentions that Van Riper was a general. This omission, I think, is owed to Gladwell's practice of presenting everyone who gets the psychology right as an enemy of the establishment, and it is hard to think of a general in that light, though in fact Van Riper is something of a maverick.
The Blue Team was equipped with an elaborate computerized decision-making tool called "Operational Net Assessment." Van Riper beat the Blue Team in the war game using low-tech, commonsense tactics: when the Blue Team knocked out the Red Team's electronic communications, for example, he used couriers on motorcycles to deliver messages. Was Van Riper's strategy a triumph of rapid cognition, as Gladwell portrays it? Operational Net Assessment was and is an experimental program for integrating military intelligence from all sources in order to dispel the "fog of war." The military is continuing to work on it. That Van Riper beat it two years ago is no more surprising than that chess champions easily beat the earliest chess-playing computers: today, in a triumph of articulate "thinking" over intuition, it is the computers that are the champs.
Gladwell also discusses alternative approaches in dating. (The procession of his anecdotes here becomes dizzying.) One is to make a list of the characteristics one desires in a date and then go looking for possible dates that fit the characteristics. The other, which experiments reveal, plausibly, to be superior, is to date a variety of people until you find someone with whom you click. The distinction is not between articulate thinking and intuitive thinking, but between deduction and induction. If you have never dated, you will not have a good idea of what you are looking for. As you date, you will acquire a better idea, and eventually you will be able to construct a useful checklist of characteristics. So this is yet another little tale that doesn't fit the ostensible subject of his book. Gladwell does not discuss "love at first sight," which would be a good illustration of the unreliability of rapid cognition.
In discussing racial discrimination, Gladwell distinguishes between "unconscious attitudes" and "conscious attitudes. That is what we choose to believe." But beliefs are not chosen. You might think it very nice to believe in the immortality of the soul, but you could not will yourself (at least if you are intellectually honest) to believe it. Elsewhere he remarks of someone that when he is excited "his eyes light up and open even wider." But eyes don't light up; it is only by opening them wider that one conveys a sense of excitement. The metaphor of eyes lighting up is harmless, but one is surprised to find it being used by a writer who is at pains to explain exactly how we read intentions in facial expressions--and it is not by observing ocular flashes.
THIS BOOK ALSO SUCCUMBS TO the fallacy that people with good ideas must be good people. Everyone in the book who gets psychology right is not only or mainly a bright person, he is also a noble human being; so there is much emphasis, Kerry-like, on Van Riper's combat performance in the Vietnam War, without explicitly mentioning that he went on to become a lieutenant-general. Such pratfalls, together with the inaptness of the stories that constitute the entirety of the book, make me wonder how far Gladwell has actually delved into the literatures that bear on his subject, which is not a new one. These include a philosophical literature illustrated by the work of Michael Polanyi on tacit knowledge and on "know how" versus "know that"; a psychological literature on cognitive capabilities and distortions; a literature in both philosophy and psychology that explores the cognitive role of the emotions; a literature in evolutionary biology that relates some of these distortions to conditions in the "ancestral environment" (the environment in which the human brain reached approximately its current level of development); a psychiatric literature on autism and other cognitive disturbances; an economic literature on the costs of acquiring and absorbing information; a literature at the intersection of philosophy, statistics, and economics that explores the rationality of basing decisions on subjective estimates of probability (Bayes's Theorem); and a literature in neuroscience that relates cognitive and emotional states to specific parts of and neuronal activities in the brain.
Taken together, these literatures demonstrate the importance of unconscious cognition, but their findings are obscured rather than elucidated by Gladwell's parade of poorly understood yarns. He wants to tell stories rather than to analyze a phenomenon. He tells them well enough, if you can stand the style. (Blink is written like a book intended for people who do not read books.) And there are interesting and even illuminating facts scattered here and there, such as the blindfold "sip" test that led Coca-Cola into the disastrous error of changing the formula for Coke so that it would taste more like Pepsi. As Gladwell explains, people do not decide what food or beverage to buy solely on the basis of taste, let alone taste in the artificial setting of a blindfold test; the taste of a food or a drink is influenced by its visual properties. So that was a case in which less information really was less, and not more. And of course he is right that we may drown in information, so that to know less about a situation may sometimes be to know more about it. It is a lesson he should have taken to heart.
-- Edward Tufte
Reasoning by sloppy analogy
One corrupt technique that I see see or hear in business presentations is "reasoning via analogy". This is where the presenter introduces an analogy -- masquerading as an aid to comprehension -- but then goes on to reason about the subject using the analogy rather than any evidence or analysis.
A (paraphrased and bowdlerised) example: "New product revenue at company X is like a rollercoaster ride. After the last quarter's sharp ramp we expect flat to down new product revenue this quarter". While historical analysis of new product revenue may suggest that it will continue to oscillate, no such evidence is presented -- nor is it explained why the past is a good predictor of the future.
-- Mathew Lodge (email)
Dequantification to smooth results
I enjoyed the discussion of Galenson's methods for dequantifying his evidence. I thought I would share a graphic I made to demonstrate what I think is a double standard in the convention for visually "quantifying" categorical versus continuous data sets:
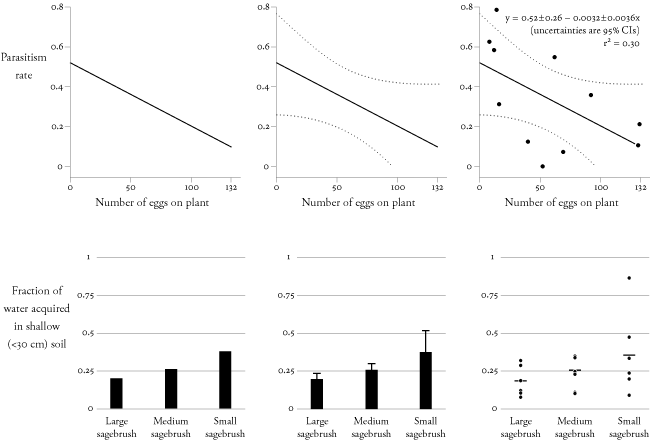
All of these panels show the relationship between one independent (predictor) variable and one dependent (response) variable, with varying levels of quantification. When showing the relationship between a continuous predictor and a continuous response (upper panels), I most often see scatterplots that have both the fitted equation and the underlying data points (top right). But for categorical predictors (lower panels), I most often see bar graphs with standard errors (bottom center). Bar graphs show only the fitted means (or other measures of central tendency) without showing the underlying data. Furthermore, standard errors are only effective if there is a large, normally distributed sample. (On page 223 of The Elements of Graphing Data, William Cleveland discusses other reasons why standard errors are graphically suboptimal.) These problems can influence interpretation. For example, in the more quantified bottom right panel, we can see that the distribution of values for 'small sagebrush' may be skewed toward higher values.
Galenson's dequantification is more flagrant, but dequantification of categorical data is more common. Because I believe that the dequantification of categorical data impedes interpretation--just as E.T. showed for Galenson's continuous data--I would be excited to see this convention overturned.
-- Anthony Darrouzet-Nardi (email)
An excellent demonstration by Kindly Contributor Anthony Darrouzet-Nardi. Showing only the path of the category means is often the sign of a serious problem in the analysis; at a minimum, it is a failure to report variability and the sensitivity of the analysis to outliers. Every editor of every scientific journal should read this contribution and act on it, by insisting that averages must be accompanied by detailed statements of variability. And the reporting of smooth curves only (without any actual data points) has always been suspicious. I believe that Professor David Freedman (statistics, Berkeley) has discussed these matters in his devastating critiques of statistical analysis.
Tukey's box-and-whiskers plot is an effort to provide a responsible summary; the bottom figures could also be represented by 3 box-and-whiskers-plots in parallel. See The Visual Display of Quantitative Information, pp. 123-125, for such an example (and for my redesign of box-and-whiskers plots).
-- Edward Tufte
Cherry picking
From today's New York Times, on the FDA advisory group hearings on cox-2 pain pills:
The panel's decisions were not good news for Pfizer, despite the rise in its stock. The company had come into the advisory committee with a strategy to deny almost entirely the notion that Celebrex increased the risks of heart attacks and strokes and to suggest that any evidence linking Bextra to such risks was shaky and irrelevant.
This strategy seemed to backfire. Panelists were incredulous that Pfizer's presentation did not include any information about a large federally sponsored trial in which patients taking Celebrex had more than three times as many heart attacks as those given a placebo.
"You're telling us that you don't have data that you published two days ago in The New England Journal?" Dr. Wood asked.
Dr. LaMattina said the panel's skepticism was unfair. In one case, Pfizer excluded data from one study because the F.D.A. said that that study would be discussed by someone else, he said.
-- Edward Tufte
Cherry picking
I remember Gerry Spence's graphical illustration of prosecutorial cherry picking (presented on CNN during the OJ prelim trial). Spence set up a table with about 70 white Dixie cups and around 10 randomly placed red Dixie cups. He said they represented all the evidence in a case, then he ham-handedly shoved all the white cups off the table and said "See, the cups are all red!"
-- Mark Bradford (email)
Grading oneself not good evidence
In this article from yesterday's New York Times on evaluating medical computer systems, note especially:
Another article in the journal looked at 100 trials of computer systems intended to assist physicians in diagnosing and treating patients. It found that most of the glowing assessments of those clinical decision support systems came from technologists who often had a hand in designing the systems. In fact, 'grading oneself' was the only factor that was consistently associated with good evaluations," observed the journal's editorial on computer technology in clinical settings, titled "Still Waiting for Godot."
Here is the full article, by Steve Lohr:
Doctors' Journal Says Computing Is No Panacea
The Bush administration and many health experts have declared that the nation's health care system needs to move quickly from paper records and prescriptions into the computer age. Modern information technology, they insist, can deliver a huge payoff: fewer medical errors, lower costs and better care.
But research papers and an editorial published today in The Journal of the American Medical Association cast doubt on the wisdom of betting heavily that information technology can transform health care anytime soon.
One paper, based on a lengthy study at a large teaching hospital, found 22 ways that a computer system for physicians could increase the risk of medication errors. Most of these problems, the authors said, were created by poorly designed software that too often ignored how doctors and nurses actually work in a hospital setting.
The likelihood of errors was increased, the paper stated, because information on patients' medications was scattered in different places in the computer system. To find a single patient's medications, the researchers found, a doctor might have to browse through up to 20 screens of information.
Among the potential causes of errors they listed were patient names' being grouped together confusingly in tiny print, drug dosages that seem arbitrary and computer crashes.
"These systems force people to wrap themselves around the technology like a pretzel instead of making sure the technology is responsive to the people doing the work," said Ross J. Koppel, the principal author of the medical journal's article on the weaknesses of computerized systems for ordering drugs and tests. Dr. Koppel is a sociologist and researcher at the Center for Clinical Epidemiology and Biostatistics at the University of Pennsylvania School of Medicine.
The research focused on ways that computer systems can unintentionally increase the risk of medical errors. The study did not try to assess whether the risks of computer systems outweigh the benefits, like the elimination of errors that had been caused by paper records and prescriptions.
Yet Dr. Koppel said he was skeptical of the belief that broad adoption of information technology could deliver big improvements in health care. "These computer systems hold great promise, but they also introduce a stunning number of faults," he said. "The emperor isn't naked, but pretty darn threadbare."
Another article in the journal looked at 100 trials of computer systems intended to assist physicians in diagnosing and treating patients. It found that most of the glowing assessments of those clinical decision support systems came from technologists who often had a hand in designing the systems.
"In fact, 'grading oneself' was the only factor that was consistently associated with good evaluations," observed the journal's editorial on computer technology in clinical settings, titled "Still Waiting for Godot."
The principal author of the editorial, Dr. Robert L. Wears, a professor in the department of emergency medicine at the University of Florida College of Medicine in Jacksonville, said the message from the research studies was that computer systems for patient records, the ordering of treatments and clinical decision support have not yet shown themselves to be mature enough to be useful in most hospitals and doctors' offices.
"These systems are as much experiments as they are solutions," said Dr. Wears, who also holds a master's degree in computer science.
The medical journal's articles, according to some physicians and technology experts, tend to be too broad in their criticisms because the technology is still developing rapidly and some of the computer systems reviewed were old.
Still, even those experts conceded that the articles raised some good points.
"They are absolutely right that the people who design these systems need to be in tune with the work," said Dr. Andrew M. Wiesenthal, a physician who oversees information technology projects at Kaiser Permanente, the nation's largest nonprofit managed care company. "But the newer systems are designed more that way."
Dr. David J. Brailer, the administration's national coordinator for health information technology, termed the articles a "useful wake-up call," though he said the findings were not surprising. In health care, as in other industries, he said, technology alone is never a lasting solution.
"The way health information technology is developed, the way it is implemented and the way it is used are what matter," Dr. Brailer said.
But Dr. Brailer did take issue with the suggestion that the Bush administration is encouraging a headlong rush to invest in health information technology.
For the next year, he said, his policy efforts will be to try to encourage the health industry to agree on common computer standards, product certification and other measures that could become the foundation for digital patient records and health computer systems.
"We're not ready yet to really accelerate investment and adoption," Dr. Brailer said. "We have about a year's worth of work."
Dr. David W. Bates, medical director for clinical and quality analysis in information systems at Partners HealthCare, a nonprofit medical group that includes Massachusetts General Hospital and Brigham and Women's Hospital, said careful planning and realistic expectations were essential for technology in health care.
"But the danger is if people take the view that computerized physician order entry and other systems are a bad idea," said Dr. Bates, who is a professor at the Harvard Medical School. "That would be throwing out the baby with the bath water."
External link to the original article
-- Edward Tufte
Why most published research findings are false
For support for the chapter above, see "Why Most Published Research Findings Are False," by John P. A. Ioannidis from the Public Library of Science:
Abstract: There is increasing concern that most current published research findings are false. The probability that a research claim is true may depend on study power and bias, the number of other studies on the same question, and, importantly, the ratio of true to no relationships among the relationships probed in each scientific field. In this framework, a research finding is less likely to be true when the studies conducted in a field are smaller; when effect sizes are smaller; when there is a greater number and lesser preselection of tested relationships; where there is greater flexibility in designs, definitions, outcomes, and analytical modes; when there is greater financial and other interest and prejudice; and when more teams are involved in a scientific field in chase of statistical significance. Simulations show that for most study designs and settings, it is more likely for a research claim to be false than true. Moreover, for many current scientific fields, claimed research findings may often be simply accurate measures of the prevailing bias. In this essay, I discuss the implications of these problems for the conduct and interpretation of research.
Note how problems such as selection effects and other biases are revealed over a series of medical studies.
The initial argument is based on a little model; the intriguing but speculative corollaries have some support based on a selected history of research literature in various medical fields. I think most of the corollaries are correct at least in the particular cases cited and are probably correct overall for many fields of study. And the paper has a lot more systematic evidence, via the citations, than my chapter. Lurking in the background is the powerful work of Tom Chalmers, whose remarkable table appears in the chapter.
The powerful defense of the scientific process is that it all eventually works out over a series of studies, at least for important matters. What emerges ultimately from the process is the wonderful capacity to identify what is true or false. So at least the truth may come out eventually. The article exemplifies this: to be able to say what is false requires knowledge of what is true.
For medical research, with enormous and demonstrable problems of false reports, there are some big costs along the way to ultimate truth. Induced to take a harmful drug based on biased and false evidence vigorously marketed, medical patients may not be consoled by the fact that the truth about the drug will discovered in the long run. Medical patients may feel they have better things to do than being part of medicine's learning and marketing curve.
Note the great virtues of the Public Library of Science here: the study is out quickly, publicly and freely available, with the citations linked to online.
-- Edward Tufte
Detecting scientific fabrication
Matching image fingerprints helped detect fraud in this account of the Woo Suk Hwang stem-cell fabrication. See articles in Telepolis and in Nature:
In one of the biggest scientific scandals of recent times, South Korea's star cloner Woo Suk Hwang last week asked to retract his landmark paper on the creation of embryonic stem cells from adult human tissue. The request, along with new doubts about his earlier work, confirms what researchers in the field were already starting to realize -- that the advance marked by Hwang's research, with all it promised for therapeutic cloning, may amount to nothing.
And the incipient retraction of 2 papers by the editor of Science.
The fabrications by Jan Hendrik Schon, the Lucent Bell Labs researcher, were in part given away by duplicative graphs:
For more than two years, condensed matter physicists were enthralled by results coming out of Bell Labs, Lucent Technologies, where researchers had developed a technique to make organic materials behave in amazing new ways: as superconductors, as lasers, as Josephson junctions, and as single-molecule transistors. (Physics Today ran news stories on some of these topics in May 2000, page 23; September 2000, page 17; January 2001, page 15; and October 2001, page 19.) Increasingly, however, enthusiasm gave way to frustration, as research groups were unable to reproduce the results. Was the technique exceedingly difficult to master, or was something else amiss?
Last spring, red flags went up. Physicists from inside and outside Bell Labs called management's attention to several sets of figures, published in different papers, that bore suspiciously strong similarities to one another (see Physics Today, July 2002, page 15). Much of the suspicion focused on Jan Hendrik Schon, a key participant in the research and the one author common to all the papers in question. With a few exceptions, Schon had applied crucial aluminum oxide insulating layers to the devices, had made the physical measurements, and had written the papers. Moreover, the sputtering machine that Schon used to apply the Al2O3 films was located, not at Bell Labs, but in his former PhD lab at the University of Konstanz in Germany.
According to Cherry Ann Murray, director of physical science research at Bell Labs, management had been made aware of some problems with Schon's work in the autumn of 2001, but at the time attributed the problems to sloppiness and poor record-keeping, not fraud. After learning this past spring about the similar-looking figures, Bell Labs management convened a committee to investigate the matter. Malcolm Beasley of Stanford University headed the committee; serving with him were Supriyo Datta of Purdue University, Herwig Kogelnik of Bell Labs, Herbert Kroemer of the University of California, Santa Barbara, and Donald Monroe of Agere Systems, a spinoff of Lucent.
Bell Labs released the committee's 127-page report in late September. The committee had examined 24 allegations (involving 25 papers) and concluded that Schon had committed scientific misconduct in 16 of those cases. "The evidence that manipulation and misrepresentation of data occurred is compelling," the report concluded. The committee also found that six of the remaining eight allegations were "troubling" but "did not provide compelling evidence" of wrongdoing. Bell Labs immediately fired Schon.
And the full internal Lucent report which is very interesting.
As someone who's refereed a lot of papers in the social sciences and statistics, I think is difficult to detect wholesale fabrication on the basis of evidence that comes with the manuscript itself. Fabrication is not the obvious competing hypothesis, well until recently, to the hypothesis advanced by the submitted article. Perhaps one principle that would apply to both these cases above is that extraordinary findings require extraordinary reviews, possibly on-site reviews of the research, before publishing. Of course extraordinary findings will doubtless receive extraordinary reviews after publication, thereby eventually detecting fabrication. Big-time fabrication of extraordinary results will consequently be caught fairly quickly; fabrication in trivial studies maybe not ever because nobody cares. Recall that the median citation rate for published scientific papers is 1.
Pre-publication reviews within the authors' research laboratories would be useful in detecting problems; there are certainly greater incentives for internal pre-publication reviews nowadays.
And what must be the elaborate self-deceptions of the fabricators as they slide down the slippery slope of fabrication, since in both these cases above the fudging appears to have lasted over several years in a series of papers?
-- Edward Tufte
In "Surely You're Joking, Mr. Feynman", Feynman talks about his revealing a new Mayan codex was indeed a fake ...
This new codex was a fake. In my lecture I pointed out that the numbers were in the style of the Madrid codex, but were 236, 90, 250, 8 - rather a coincidence! Out of the hundred thousand books originally made we get another fragment, and it has the same thing on it as the other fragmetns! It was obviously, again, one of these put-together things which had nothing original in it.Feynman then goes into the psychology of how one could go about faking a discovery.
These people who copy things never have the courage to make up something really different. If you find something that is really new, it's got to have something different. A real hoax would be to take something like the period of Mars, invent a mythology to go with it, and then draw pictures associated with this mythology with numbers appropriate to Mars - not in an obvious fashion; rather, have tables of multiples of the period with some mysterious "errors," and so on. The numbers should have to be worked out a little bit. Then people would say, "Geez! This has to do with Mars!" In addition, there should be a number of things in it that are not understandable, and are not exactly like what has been seen before. That would make a good fake.Michael Round
-- Michael Round (email)
Detective work at Science:
Panel recommends changes at Science
Science should revamp its review process to help prevent research fraud, according to a report from a panel of outside experts made public yesterday (November 28). The group recommended that the journal create a procedure for flagging papers that need extra scrutiny and demand more information about individual authors' contributions to each paper, among other measures. The independent assessment committee was convened by Science earlier this year after the journal retracted work by Hwang Woo-suk in which the South Korean researcher fraudulently claimed to be able to produce human embryonic stem cells from adult cells. The committee wrote that Science's editors followed the journal's procedures in reviewing the research, but that the current process, based on trust, is inadequate to deal with cases of intentional deception. The committee recommended four key changes, including implementation of a formal risk-assessment procedure to "explicitly ask questions about the probability that the work might be intentionally deceptive." As part of the procedure, papers likely to garner a great deal of public attention should get extra scrutiny, the report states. Science should also develop a procedure for clarifying each author's specific contribution to a paper; increase the information made available as part of the published supporting material for papers; and work to establish common standards with other journals, the panel advised. Donald Kennedy, Science's editor-in-chief, said during a conference call with the media yesterday that he found the report "very thoughtful and intelligent," but that the journal is still reviewing the recommendations and has yet to officially decide whether and how to implement them. Change often comes at a price, Kennedy cautioned. "There will be social costs associated with the loss of the tradition of trust, and we need to ask ourselves whether interventions in the interest of detecting falsification might not be costing the system more than the occasional retraction would," he said. Nonetheless, Kennedy suggested that the journal would probably adopt the recommendations in some form. Regarding the risk-assessment component, he said the editors would likely ask themselves the following questions to determine whether a paper needs extra scrutiny: "Is it a highly unexpected or counterintuitive result that would be likely to break a new path in a whole field of science? Does it bear significantly on a reasonably hot set of possible policy choices, as would be the case for a paper in the field of stem cells, or for a paper on climate change? Has it already attracted a great deal of external attention that would make it a matter of especially intense public interest?" Another issue raised during the conference call was whether papers from outside the US should be considered in need of extra care because language barriers and cultural differences can make fraud harder to detect. Kennedy noted that the review of the Hwang research was complicated by these factors. "On the other hand, we donin't want to engage in profiling," he said. "It would really be unfair if we started looking extra hard at papers from emerging scientific powers in countries like South Korea." Kennedy said he expects the number of papers falling into the high-risk category would be relatively small, "perhaps 10 a year or less." The special attention given to such papers would likely include more demands for original data and original images, among other things. "We'll be working these procedures out and will seek commentary from the scientific community as we do so," he noted.
-- Edward Tufte
Funding our conclusions
From PLoS Medicine, an article on the relationship between funding source and conclusions reached.
Here's the summary of the article, which replicates similar results in drug research:
Relationship between Funding Source and Conclusion among Nutrition-Related Scientific Articles
Lenard I. Lesser, Cara B. Ebbeling, Merrill Goozner, David Wypij, David S. Ludwig
Background
Industrial support of biomedical research may bias scientific conclusions, as demonstrated by recent analyses of pharmaceutical studies. However, this issue has not been systematically examined in the area of nutrition research. The purpose of this study is to characterize financial sponsorship of scientific articles addressing the health effects of three commonly consumed beverages, and to determine how sponsorship affects published conclusions.
Methods and Findings
Medline searches of worldwide literature were used to identify three article types (interventional studies, observational studies, and scientific reviews) about soft drinks, juice, and milk published between 1 January, 1999 and 31 December, 2003. Financial sponsorship and article conclusions were classified by independent groups of coinvestigators. The relationship between sponsorship and conclusions was explored by exact tests and regression analyses, controlling for covariates. 206 articles were included in the study, of which 111 declared financial sponsorship. Of these, 22% had all industry funding, 47% had no industry funding, and 32% had mixed funding. Funding source was significantly related to conclusions when considering all article types (p = 0.037). For interventional studies, the proportion with unfavorable conclusions was 0% for all industry funding versus 37% for no industry funding (p = 0.009). The odds ratio of a favorable versus unfavorable conclusion was 7.61 (95% confidence interval 1.27 to 45.73), comparing articles with all industry funding to no industry funding.
Conclusions
Industry funding of nutrition-related scientific articles may bias conclusions in favor of sponsors' products, with potentially significant implications for public health.
-- Edward Tufte
"A Devout Wish"
Talking, rational, telepathic animals one more time. See the article on the African Grey Parrot by Robert Todd Carroll, The Skeptic's Dictionary.

Richard Feynman's principle "The first principle is that you must not fool yourself--and you are the easiest person to fool" might be revised to cover the propagation of foolishness:
"The first principle is that you must not fool yourself (and you are the easiest person to fool), but also that you must not attempt to fool others with your foolishness."
-- Edward Tufte
See David Sanger's article in the New York Times on how reporters are handling leaks and intelligence briefings in light of getting fooled in recent years.
More than ever it is building on reporters whose job it is to go beyond reporting the latest conclusions of a secret National Intelligence Estimate and explain to their readers whether those conclusions -- and the always-murky data attached to them -- are reasonable, or being twisted to fit a policy agenda.
None of this started with Mr. Libby, of course, but his case centered on a brief window in time that summer, when the White House was forced to admit that it couldn't support President Bush's assertion that Saddam Hussein had sought uranium in Africa. Amid nasty finger-pointing between the White House and the C.I.A., the administration suddenly had to declassify its intelligence findings, in a desperate effort to explain why Mr. Bush and Vice President Dick Cheney made so many false assertions. Mr. Libby was consumed in that effort.
Ever since, no one in the administration has been able to stuff the intelligence genie back into the C.I.A.'s black bag. And so whether the subject is yellowcake in Africa, centrifuges in North Korea, a drawing of two hemispheres of uranium in Iran, or the pedigree of roadside bombs in Iraq, there is this different dynamic at work.
The understandable instinct to say, "Sorry, it's classified," has been tempered by the belated realization of the administration that its credibility has suffered so much damage, at home and abroad, that it has little choice but to reveal a broader sampling of the evidence that it reflexively stamps Top Secret. For the first time in memory in dealing with a White House that prizes "no comments," it is easier to squeeze officials into explaining how they reached their conclusions -- and who dissented.
Nicholas Lemann, the dean of Columbia Journalism School, teaches a course called "Evidence and Inference," and says he is now "hammering into the head of everyone around here that when someone tells you something, you have to say, 'Walk me through how you came to your conclusion.' "
-- Edward Tufte
I have been teaching bioscientists for the past 15 years how to conduct QUANTITATIVE experiments using microscopes. The technical solution is easy (stereology) but the persistent problem we have is pareidolia (wikipedia describes this as "involving a vague and random stimulus, often as image or sound, being perceived as significant"). People read things into 2D images of 3D structure that either cannot be or are not there. How does pareidolia affect the practice of information visualisation and display?
-- MR (email)
Wikipedia List of Cognitive Biases (Please read this before continuing below.)
After reading through the list, one wonders how people ever get anything right. That's called the "cognitive biases bias," or maybe the "skepticism bias" or "paralysis by analysis."
There's also the "bias bias," where lists of cognitive biases are used as rhetorical weapons to attack any analysis, regardless of the quality of the analysis. The previous sentence then could be countered by describing it as an example of the "bias bias bias," and so on in an boring infinite regress of tu quoque disputation, or "slashdot."
The way out is to demand evidence for a claim of bias, and not just to rely on an assertion of bias. Thus the critic is responsible for providing good evidence for the claim of bias and by demonstrating that the claimed bias is relevant to the findings of the original work. Of course that evidence may be biased. . . . And, at some point, we may have to act what evidence we have in hand, although such evidence may have methodological imperfections.
The effects of cognitive biases are diluted by peer review in scholarship, by the extent of opportunity for advancing alternative explanations, by public review, by the presence of good lists of cognitive biases, and, most of all, by additional evidence.
The points above might well be included in the Wikipedia entry, in order to dilute the bias ("deformation professionnelle") of the bias analysis profession.
In Wikpedia, I particularly appreciated:
Deformation professionnelle is a French phrase, meaning a tendency to look at things from the point of view of one's own profession and forget a broader perspective. It is a pun on the expression, "formation professionelle," meaning "professional training." The implication is that, all (or most) professional training results to some extent in a distortion of the way the professional views the world.
Thus the essay "The Economisting of Art" is about what I view as the early limits in the microeconomic approach to understanding the prices of art at auction.
In my wanderings through various fields over the years, I have become particularly aware of deformation professionnelle and, indeed, have tried to do fresh things that break through local professional customs, parochialisms, and deformations.
-- Edward Tufte
If Sufficiently Tortured, Data Will Confess to Anything
In his consistently excellent Economists View
blog, Professor Mark Thoma points out an excellent - and amazingly transparent - example of corrupting visual evidence to advance a preconceived point of view. That this amazingly innumerate chart comes from the Wall Street Journal (a presumably respected member of the mainstream media) makes this even more amazing.
 |
Determined to see a Laffer curve in there somewhere, the author blissfully ignores almost all of the data points and confidently draws the one curve that justifies his preconceived agenda that corporate taxes are too high! Note how the curve starts at the artificial (0,0) data point for the UAE, goes to the clear Norway outlier and then drops in an arbitrarily precipitous manner. Arbitrary, that is, other than the fact that the US finds itself to the right of the curve, thereby confirming the authors opinion that US corporate taxes are too high and that the government could increase revenue by decreasing it. Q.E.D.!
Mark demonstrates how an alternative linear function - also somewhat arbitrary, though arguably more defensible - would prove the (not exactly radical) notion that government revenue tends to increase with increased tax rates. But that is exactly the oposite of what the article's author wanted to prove...
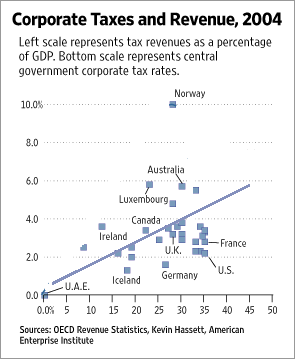 |
Further evidence that data will confess to anything if you torture it enough!
-- Zuil Serip (email)
Data sharing denied
Andrew Vickers, a biostatistican at Sloan-Kettering, reports on failures to share data sets here in the New York Times:
Given the enormous physical, emotional and financial toll of cancer, one might expect researchers to promote the free and open exchange of information. The patients who volunteer for cancer trials often suffer through painful procedures and harsh experimental treatments in the hope of hastening a cure. The data they provide ought to belong to all of us. Yet cancer researchers typically treat it as their personal property.
The reasons cited by researchers unwilling to share their data -- the difficulty of putting together a data set, the chance that the data might be analyzed using invalid methods -- were trivial. Preparing the data set would have to be done anyway in order to publish a paper, and the validity of analytic methods are surely a judgment for the scientific community as a whole. This is, Vickers concludes, an indication that "the real issue here has more to do with status and career than with any loftier considerations. Scientists don't want to be scooped by their own data, or have someone else challenge their conclusions with a new analysis." However, this is exactly what cancer patients need -- to have new results published as quickly as possible, encouraging a robust debate on the merits of key research findings.
-- Edward Tufte
Financial engineering
Steve Lohr in The New York Times, "In Modeling Risk, the Human Factor Was Left Out":
Models used on Wall Street not only included a lot of wishful thinking about house prices, but also depended a great deal on other people's beliefs. These behavioral factors are very hard to model.
Indeed, the behavioral uncertainty added to the escalating complexity of financial markets help explain the failure in risk management. The quantitative models typically have their origins in academia and often the physical sciences. In academia, the focus is on problems that can be solved, proved and published -- not messy, intractable challenges. In science, the models derive from particle flows in a liquid or a gas, which conform to the neat, crisp laws of physics.
Not so in financial modeling. Emanuel Derman is a physicist who became a managing director at Goldman Sachs, a quant whose name is on a few financial models and author of "My Life as a Quant -- Reflections on Physics and Finance" (Wiley, 2004). In a paper that will be published next year in a professional journal, Mr. Derman writes, "To confuse the model with the world is to embrace a future disaster driven by the belief that humans obey mathematical rules."
Yet blaming the models for their shortcomings, he said in an interview, seems misguided. "The models were more a tool of enthusiasm than a cause of the crisis," said Mr. Derman, who is a professor at Columbia University.
Better modeling would have helped, the article concludes, but the ultimate cause of the crisis lay with Wall Street senior management, who chose to disregard warnings and chase profits in the good times.
-- Edward Tufte
Real problems here
An extraordinary report by Gardiner Harris of The New York Times, a ghastly brew of a Harvard University child psychiatrist, big pharma (Johnson & Johnson), and pediatric (!) anti-psychotic drugs:
Dr. Biederman's work helped to fuel a fortyfold increase from 1994 to 2003 in the diagnosis of pediatric bipolar disorder and a rapid rise in the use of powerful, risky and expensive antipsychotic medicines in children. Although many of his studies are small and often financed by drug makers, Dr. Biederman has had a vast influence on the field largely because of his position at one of the most prestigious medical institutions.Now thousands of parents have sued the AstraZeneca, Eli Lilly and Johnson & Johnson, claiming that their children were injured after taking these risky antipsychotic medicines; they also claim that the companies minimized the risks of the drugs. Documents made public as part of the lawsuits offer a glimpse into Dr. Biederman's relationship to these drug companies, who provided him with at least $1.4 million in outside income. For example,
A June 2002 e-mail message to Dr. Biederman from Dr. Gahan Pandina, a Johnson & Johnson executive, included a brief abstract of a study of Risperdal in children with disruptive behavior disorder. The message said the study was intended to be presented at the 2002 annual meeting of the American Academy of Child and Adolescent Psychiatry.
"We have generated a review abstract," Dr. Pandina wrote, "but I must review this longer abstract before passing this along."
One problem with the study, Dr. Pandina wrote, is that the children given placebos and those given Risperdal both improved significantly. "So, if you could," Dr. Pandina added, "please give some thought to how to handle this issue if it occurs."
The draft abstract that Dr. Pandina put in the e-mail message, however, stated that only the children given Risperdal improved, while those given placebos did not. Dr. Pandina asked Dr. Biederman to sign a form listing himself as the author so the company could present the study to the conference, according to the message.
"I will review this morning," responded Dr. Biederman, according to the documents. "I will be happy to sign the forms if you could kindly send them to me." The documents do not make clear whether he approved the final summary of the brief abstract in similar form or asked to read the longer report on the study.
-- Edward Tufte
Corrupt results in physics textbooks
See "Introductory physics: The new scholasticism" by Sanjoy Mahajan, Physics Department, University of Cambridge, and David W. Hogg, Physics Department, New York University:
Most introductory physics textbooks neglect air resistance in situations where an astute student can observe that it dominates the dynamics. We give examples from many books. Using dimensional analysis we discuss how to estimate the relative importance of air resistance and gravity. The discussion can be used to mitigate the baleful influence of these textbooks. Incorrectly neglecting air resistance is one of their many unphysical teachings. Shouldn't a physics textbook teach correct physics?
-- Edward Tufte
I found the article about air resistance very interesting, and, like the authors of one of the texts quoted, I was surprised at how big the effect is.
A similar (more elementary) case in biology where the textbooks say something that contradicts the everyday experience of some readers is the description of human eye colour in elementary accounts of Mendelian genetics. The general idea is that brown eyes are dominant over blue, so if both parents have blue eyes then so do their children; if either parent is homozygotic for brown eyes then the children have brown eyes, but if either or both parents are heterozygotic the child's eyes may be either brown or blue. All that is true enough if we confine attention to people whose eyes are bright blue or dark brown, but that leaves out a lot of people who will read the textbook account and wonder how it applies to them. My eyes are neither brown nor blue, and there are plenty of other people who can say the same. Of course, it's fine for a textbook to describe the simplest case, but it's important to say that it is the simplest case and that real life is often more complicated.
-- Athel Cornish-Bowden (email)
BP oil spill recovery presentation
A BP vice president confusing integral and derivative here.
As the link explains,
In a new video explaining the "top kill" strategy, BP senior vice president Kent Wells shows this graphic for the amount of oil being captured from the Deepwater Horizon by the suction tube. Wells says that BP has been tweaking the tube to "maximize" the collection of oil from the gushing well.
"There's been a lot of questions around how much oil is being collected," Well says at around 4:11, pointing to the graph. But if you look closely at the chart ... those green bars go up because the tube has been in place since May 16. The longer it stays, the more gallons it collects. It's not necessarily collecting more oil on successive days, let alone "most" of the oil as Wells says they're trying to do.
Wells mentions some of the technical adjustments to the siphon, then says, "Here you can see how we've continued to ramp up." If only that were so.
From commenter Brandon Green: "Wow, if you look at the tapering off in the last few bars, it would seem the graph proves the exact opposite point they are trying to use it to make - that they are somehow managing to become LESS efficient at collecting the oil."
-- Anonymous (email)
|
||||||