Measuring website traffic
Peter Edmonston of The New York Times has an interesting article about how Forbes.com apparently exaggerates the number of unique visitors to the website.
During the dot-bomb times, advertised measures of website activities were bizarrely corrupt. A few years ago NASA (and its then-director) reported that their website during a Mars visit had more “hits” than there are people on Earth.
I gather that “unique visitors” and “pageviews” provide some reasonable measures of website traffic. But the time period for measuring “unique” should be specified, such as unique visitors each day. (Is that what “unique” usually means?) For smaller websites, “pageviews” are substantially inflated by search engine crawlers; our site often gets 1,400 pageviews per day from Google alone and a good many spurious pageviews from spammers, email-address harvesters, and the like. It’s just computers talking to other computers, not pageviews by a human.
Traffic measures can also be generated by user polling. I understand that Alexa provides estimates of traffic counts for many websites, but it fails to document that information concerning its biased methodology, which only polls nonrandomly selected users of Microsoft Windows.
Can our Kindly Contributors provide some authoritative information or links on this matter (especially from the point of view of data quality and data integrity)?

To my mind, a great blog is by an industry leader, Avinash Kaushik. Well written, clear thinking, humerous, humble, backed by abudant experience… on all manner of issues around web analytics – he often talks about how to think beyond mere unique views. Avinash is a lead something (can’t remember his title) at Intuit, who do Quicken, Turbotax and some other heafty products.
This post talks about two methods of understanding web traffic. Check out other posts though!
http://www.kaushik.net/avinash/2006/08/competitive-intelligence-analysis-why-what-how-to-choose.html
I manage a website for the University of Maryland Medical System that gets around 75,000 visits and 175,000 page views a day. We use two reporting tools, Net Tracker and WebTrends – standard analysis packages widely used by Web departments. These are adequate tools, but the raw log files have to be scrubbed before they can create meaningful reports.
We spend about 30 minutes each day reviewing the previous night’s logs and deleting traffic from spiders, bots and the like (good ones like Google and the bad ones described above). Our filter list has hundreds of entries, and two or three new ones pop up daily.
We also delete requests for images and other non-content files. When the process is over the new log file is 5% of its original size and ready for processing.
There are four commonly used terms when discussing site traffic: hits, page views, visits and unique visitors
“Hits” is meaningless because every file requested is a hit, including the numerous graphics included in a typical web page.
A visit comprises the activity on a site caused by single computer within an arbitrary time-out period. The industry standard is 30 minutes. A combination of the IP address and a “cookie” helps identify and track the usage. This identifying information is also used to track unique visitors.
As an example – Betty visits the http://www.umm.edu site in the morning and looks at 10 pages of content. Each page has nine images plus the core html file. She comes back in the afternoon and looks at 5 more pages. This is how her session would be counted if we tracked image requests:
1 Unique Visitor – 2 Visits – 15 Page Views – 150 Hits
In the real world there are dozens of technical issues that muddy the waters – proxy servers, RSS feeds, AJAX page refreshing, etc. It’s a confusing mess. For me, the only reliable metric is page views, and that’s only valid if the raw data has been scrubbed.
I hope this is helpful,
Ed Bennett
We all know that traffic shows an exponential distribution so semilog plots can break out interesting groups. Here’s my interpretation of one month’s logs. Notice the gray river of time-dependent traffic just drops off at a little over 1000 hits. I think this is rate-limited computer-to-computer talk.
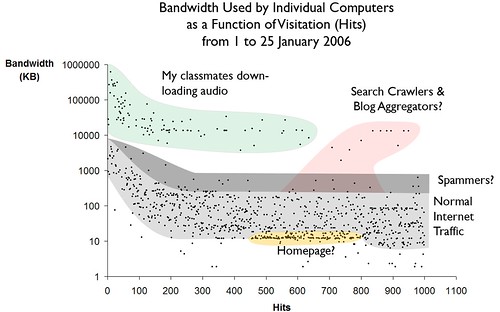
From Class Lecture Audio Statistics
Awstats is a superb log file analysis tool. It is open source and I have been very pleased with it’s ability to wring quite a bit out of log files. One thing I would think should be standard practice is to filter for humans by user-agent. These can always be faked (most of a log file’s contents comes from client-originated packets), but how many people, even spammers, really care enough to change their declared user-agent? User-agents are usually “Internet Explorer” or “Mozilla” or “Gecko” or “Firefox” or “googlebot”. What are the computer user-agents? Here’s a listing.
Many webstats companies, like Sitemeter and ClustrMaps, use another method: you put their code in your page that directs the user-agent to download a small image from their servers, which allows them to get packet information from your users as well. Part of the idea is that many non-human user-agents aren’t much interested in image data since its much harder to parse.
Surveys seem useful, but how do you get control groups? In demographic surveys, the usual method is to pick random blocks in the grid to survey house-by-house, and then, in the other blocks, the survey teams survey only one-in-four or one-in-five. What are those ‘house-by-house’ blocks called? Controls? How would you construct ‘control’ blocks of website visitors? You could target known blocks of IP addresses that are controlled by, say, Cox Cable, and seek 100% response from blocks of those IP addresses. Of course, the ISP’s DHCP server reassigns the user machines every time they reconnect, so even ISP cooperativity would be useless unless the ISP agreed to give you a slice-in-time, user-level picture, complete with some independent ‘reach-out-and-touch-them’ information, like phone numbers.
Perhaps one question to ask, one that somebody might actually be able to answer, is what fraction of file requests come from humans? A university with on-campus housing might have someone in their IT department who would be able to provide some insight on that by comparing “outside” traffic to traffic they are delivering to the dorms. This would require some pattern-matching to find things like servers being run from within the dorms, etc, but perhaps a small enough problem to be tractable.
The above link is about measurement of web traffic for marketing effectiveness; how about some material on the meaning of what non-fiction sites see in their daily logs?
Not exactly on topic, but visually intriguing, are “heatmaps” of hits on a given page.
Originally found via the Ruby on Rails blog, Crazy Egg provides a service-based solution, while this Ruby Inside article gives you a do-it-yourself recipe that has just become a full-fledged open source project: Clickmaps.
Unfortunately, they are currently using the dreaded rainbow colormap for dislaying their hit quantities.
I’m not sure what kind of info you’re looking for E.T. so if you’d like to reiterate then I could answer more directly. I’ve been doing online audience measurement and website analytics for 10 years. I hope we can keep this thread going because I attended your seminar in NYC last year because your work is so valuable to web analytics professionals.
JavaScript tags are now the most common way for businesses to measure the activity on their websites. It’s been known for quite some time that log file software are prone to many inaccuracies for the reasons mentione above. Some business use a hybrid method of both log files and tags. “Everything”, including your definitions for sessions/visits, is dependent on what you want to learn because you can get so much information.
A growing number of people use NoScript as a security measure; the likely consequence is that more people will only allow javascript from the sites they’re interested in, defeating, by default, javascript as a method of third-party traffic analysis and user-monitoring. I wouldn’t be surprised if NoScript is incorporated into future browsers.
Adblock Plus and its extensions also work against third-party traffic analysis by blocking images, like banner ads.
NoScript and Adblock Plus are Firefox plugins.